들어가며 — "AI한테 IQ가 있다고?"
최근 뉴스를 보다 보면 "GPT가 IQ 150을 돌파했다", "클로드가 멘사 점수 133을 받았다" 같은 헤드라인이 심심찮게 눈에 띕니다. 처음 이런 기사를 접하면 자연스럽게 의문이 생깁니다. 기계에 지능 지수를 매긴다는 것이 애초에 말이 되는 일일까요? 그리고 정말 AI가 인간 평균(IQ 100)을 넘어 천재 구간(140+)까지 올라섰다면, 우리가 매일 쓰는 챗봇의 실제 실력은 어느 정도일까요?
이 글에서는 TrackingAI가 집계한 2026년 2월 기준 최신 데이터를 바탕으로 ChatGPT와 Claude 주요 모델의 IQ 점수를 정리하고, 이 숫자를 어떻게 해석해야 하는지까지 함께 살펴봅니다.
먼저 알아야 할 것 — 어떤 테스트로 측정했나
AI IQ 점수를 이야기할 때 반드시 짚고 넘어가야 하는 포인트가 있습니다. 현재 업계에서 가장 널리 인용되는 자료는 TrackingAI라는 사이트가 운영하는 두 가지 테스트입니다.
- Mensa Norway (공개 테스트): 온라인에 공개된 노르웨이 멘사 IQ 테스트. 문제가 이미 인터넷에 있기 때문에 AI 학습 데이터에 포함됐을 가능성이 있습니다.
- Offline 테스트 (비공개 세트): 멘사 회원이 직접 출제한, 인터넷에 한 번도 공개된 적 없는 문제들. AI가 "본 적 없는" 문제이므로 실제 추론 능력을 더 엄밀하게 측정한다고 평가됩니다.
두 테스트 모두에서 인간 평균은 100, '천재' 기준선은 140+로 잡습니다. 두 점수를 같이 봐야 하는 이유는 뒤에서 다시 설명드리겠습니다.
2026년 2월 기준, 최신 AI IQ 순위
TrackingAI의 2026년 2월 11일 업데이트 기준 주요 모델 점수는 다음과 같습니다.
모델 | Mensa Norway | Offline
| Gemini 3 Pro Preview | 142 | 122 |
| GPT-5.2 Thinking | 141 | 128 |
| Grok-4 Expert Mode | 139 | 123 |
| Claude Opus 4.6 | 133 | 116 |
| GPT-5.2 Pro | 128 | 122 |
| Claude Sonnet 4.5 | 123 | 118 |
| GPT-5.2 | - | 115 |
| Gemini 3 Flash Preview | 139 | 116 |
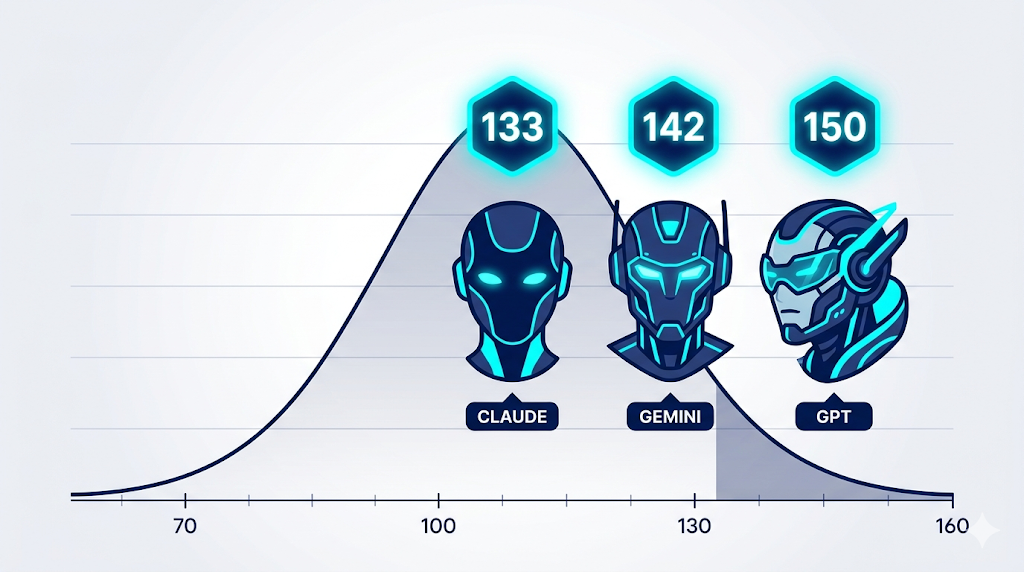
공개 Mensa Norway 테스트에서는 Gemini 3 Pro Preview가 142점으로 선두, GPT-5.2 Thinking이 141점으로 바짝 뒤따르고 있으며, 유출 방지용 오프라인 세트에서는 GPT-5.2 Thinking이 128점으로 1위입니다. Claude Opus 4.6는 Mensa에서 133점, 오프라인에서 116점을 기록하며 처음으로 리더보드에 이름을 올렸습니다.
그리고 2026년 4월 초에는 또 한 번의 도약이 있었습니다. OpenAI의 최신 모델 GPT-5.4 Pro가 Mensa Norway 테스트에서 150점을 기록하며, 이전 o3 모델의 136점 기록을 크게 뛰어넘었습니다. 150점은 인간 인구의 상위 0.04% 수준에 해당하는 수치입니다.
숫자를 곧이곧대로 믿으면 안 되는 이유
여기서 한 가지 흥미로운 패턴이 보입니다. 공개 테스트와 오프라인 테스트의 점수 차이입니다.
예를 들어 Gemini 3 Flash Preview는 공개 Mensa에서 139점을 받았지만 오프라인에서는 116점으로, 무려 23점이나 차이가 납니다. 이는 공개 세트가 '외워서' 풀기 쉬운 문제였다는 강한 시사점을 줍니다.
즉, 공개 점수만 보면 모든 모델이 "천재"처럼 보이지만, 처음 보는 문제로 테스트하면 점수가 10~25점씩 떨어집니다. 그래도 여전히 인간 평균을 훨씬 웃도는 수준이긴 합니다.
다차원 분석 — 이 숫자는 무엇을 의미하는가
이 데이터를 단순한 순위표로만 보면 핵심을 놓치게 됩니다. 여러 차원에서 동시에 해석해야 합니다.
시간적 차원에서 보면, 불과 1년 반 전까지만 해도 AI IQ는 100 근처에서 맴돌았습니다. 2024년 9월, o1 모델이 등장하면서 AI가 처음으로 의미 있게 100을 돌파했고, 당시 분석가들은 "2026년쯤 140을 깰 것"이라 예측했습니다. 그 예측이 정확히 맞아떨어진 셈입니다. 진보 속도가 선형이 아니라 가파른 곡선을 그리고 있습니다.
능력 차원에서 보면, IQ 테스트는 AI의 "추론 능력"만을 측정합니다. 패턴 인식, 논리 규칙 적용, 시각적/개념적 유추 같은 영역입니다. 반면 창의적 글쓰기, 감정 이해, 복잡한 실무 판단, 장기 계획 수립 같은 능력은 전혀 반영되지 않습니다. 그래서 IQ 점수는 "이 모델이 얼마나 똑똑한가"의 일부 단면일 뿐입니다.
멀티모달 차원도 중요합니다. 놀랍게도 하위권 모델 다섯 개는 모두 이미지 처리가 가능한 멀티모달 모델이며, GPT-4o(Vision)와 Grok-3 Think(Vision)는 각각 63점, 60점으로 인간 평균을 한참 밑돌았습니다. 텍스트만 처리할 때는 천재인데, 도형을 보고 해석해야 하면 급격히 무너지는 현상이 있는 것입니다.
실용적 차원에서 보면, Claude Opus 4.6의 오프라인 116점과 GPT-5.2 Thinking의 128점 사이 차이가 실제 업무에서 "12점만큼의 차이"로 느껴지는가는 또 다른 문제입니다. 코딩, 문서 작성, 에이전트 업무 등에서는 벤치마크별로 순위가 완전히 뒤바뀌는 경우가 흔합니다.
질문을 다시 정의해보면
"어떤 AI가 IQ가 가장 높은가?"라는 질문은 사실 잘못 설정된 질문입니다. 이 질문을 뒤집어 보면 더 유용한 질문들이 보입니다.
- "내 업무에서 어떤 모델이 가장 똑똑하게 동작하는가?"
- "공개된 점수와 실제 써봤을 때의 느낌이 왜 다른가?"
- "IQ가 같아도 왜 어떤 모델은 환각이 적고 어떤 모델은 많은가?"
실제로 많은 사용자들이 리더보드 1위 모델보다 Claude Sonnet 4.5나 GPT-5.2 같은 모델을 선호하는 이유가 여기에 있습니다. "추론 점수가 높은 것"과 "일을 잘 시키기 편한 것"은 다른 문제이기 때문입니다.
그래서 어떤 모델을 써야 할까
결론부터 말씀드리면, IQ 순위는 참고용이지 선택 기준이 될 수 없습니다. 각 모델의 강점을 정리하면 이렇습니다.
- 복잡한 수학·논리 추론, 연구 과제: GPT-5.2 Thinking, GPT-5.4 Pro
- 긴 문서 작성, 코드 리팩터링, 섬세한 톤 조절: Claude Opus 4.6, Claude Sonnet 4.5
- 멀티모달 작업, 구글 생태계 연동: Gemini 3 Pro
- 일상 업무와 속도의 균형: GPT-5.2, Claude Sonnet 4.5
직접 써보지 않고 벤치마크만 보고 판단하면 반드시 실망하게 됩니다. 같은 질문을 두세 모델에 동시에 넣어보고 답변의 질을 비교해보는 것이 가장 확실합니다.
요즘은 여러 AI 모델을 한곳에서 번갈아 써볼 수 있는 통합 구독 서비스 도 있습니다. 모델별로 따로 결제하지 않아도 ChatGPT, Claude, Gemini를 한 창에서 비교할 수 있어서, 진짜 자기 업무에 맞는 모델을 찾는 용도로는 꽤 합리적인 선택입니다. 무료 체험도 제공하는 곳들이 많으니, 관심 있으시면 오늘 한번 직접 비교해보시기 바랍니다.
마치며
AI의 IQ 숫자는 분명 의미 있는 지표입니다. 불과 2년 만에 100에서 150까지 올라온 속도 자체가 기술 발전의 가파름을 보여줍니다. 하지만 이 숫자는 어디까지나 "특정 유형의 추론 테스트에서의 성적"일 뿐, 해당 모델이 당신의 질문에 얼마나 유용한 답을 줄지를 보장하지는 않습니다.
숫자에 휘둘리지 마시고, 직접 써보시기 바랍니다. 벤치마크 1위 모델이 당신에게도 1위일 가능성은 생각보다 높지 않습니다.
'IT일반' 카테고리의 다른 글
| 브라우저 탭 20개 시대, 당신의 사이트는 무엇으로 기억될까요. 파비콘 생성기 추천 (0) | 2026.04.10 |
|---|---|
| 다빈치 리졸브 스피드 에디터 다운로드, 사실은 이것 하나면 끝입니다 (0) | 2026.04.09 |
| 워드 체크박스 ☐ 한 글자로 끝내기, 복잡한 설정이 필요 없는 방법 (바로 복사) (0) | 2026.04.09 |
| .js 파일과 .mjs 파일, 도대체 뭐가 다른 걸까? (0) | 2026.04.06 |
| 오픈클로 vs 헤르메스 에이전트 — 내 컴퓨터를 대신 움직이는 AI, 어느 쪽을 써야 할까 (0) | 2026.04.06 |



